Loader 分析与优化
通常来说,优化 Loader 是比较常见的优化 Rspack 或 webpack 编译性能的方式,而大部分情况下,我们除了通过替换更快的 loader 之外,常见的手段就是给 loader 设置 module.rule.exclude 来减少执行。
而 Rsdoctor 提供了两个核心模块(Loader Overall / Loader Analysis)来帮助你根据 Loader 的调用信息进行深度优化。
如何分析?
不管是哪种手段去优化 Loader,我们都需要拿到关于 Loader 的数据信息,比如 「某个 Loader 编译了哪些文件」、「编译某些文件的耗时信息」 等等,我们才能更精确的进行优化。
文件树结构
我们通过 Rsdoctor 提供的 Loader Analysis 模块,我们可以看到在整个编译过程中所有经过 Loader 的文件组成的树结构,如下图所示:
分析目录
通过 点击选中目录 可以在文件树的右侧,看到当前选中目录下所有 Loader 的耗时统计数据(预估耗时),即 "Statistics of ***" 的卡片内容如下图所示:
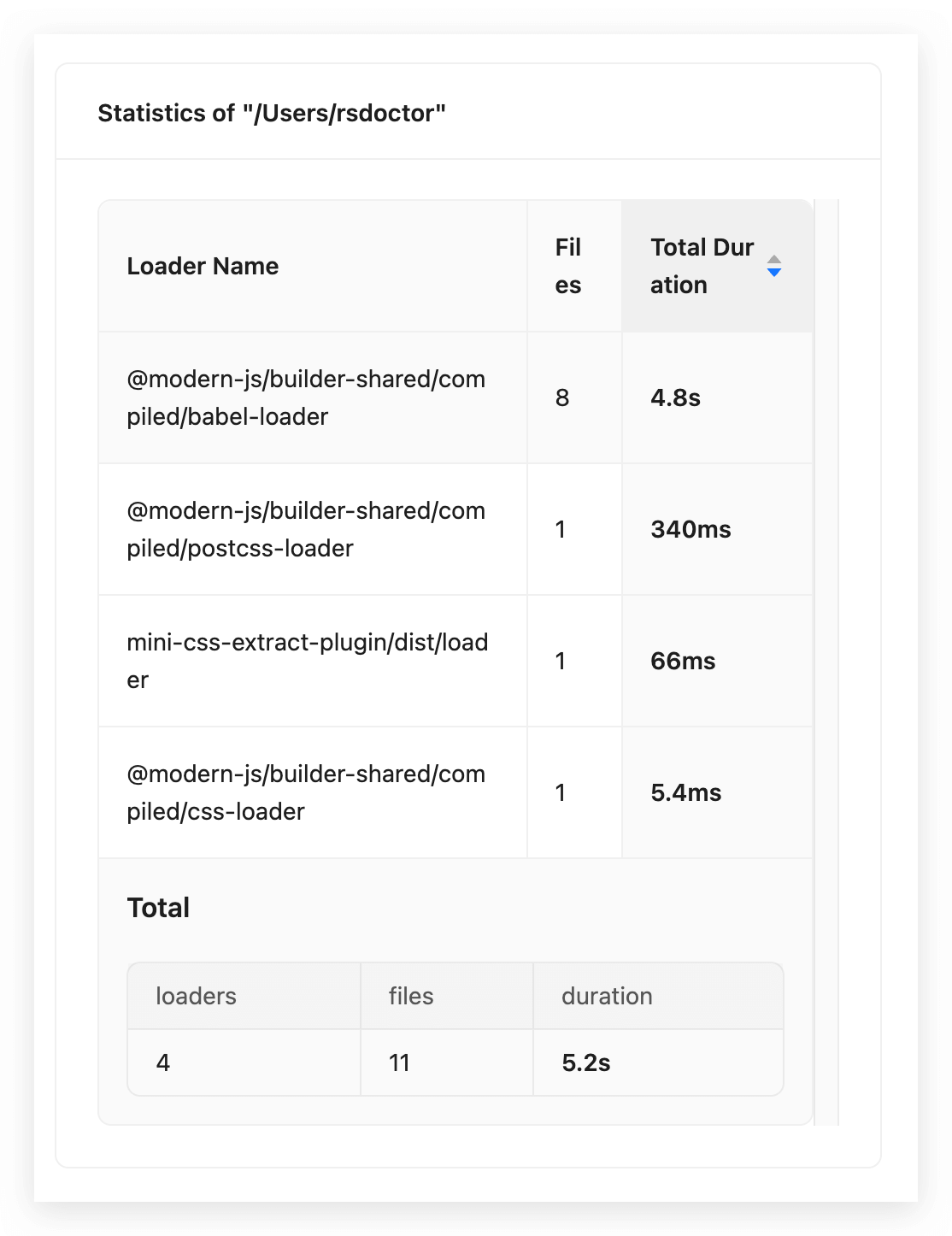
我们可以很直观的知道这个文件夹下的耗时数据,比如 某个 Loader 处理的文件数以及预估耗时,以及所有数据的总和,从而进一步帮助我们去决策如何优化 Loader。
通常来说,在 node_modules 内的一些三方库目录,我们可以很容易跟据 Loader 的耗时信息,来判断我们是不是有必要要给这个目录设置 module.rule.exclude,来减少比如常见的耗时长的 babel-loader 的执行。
分析文件
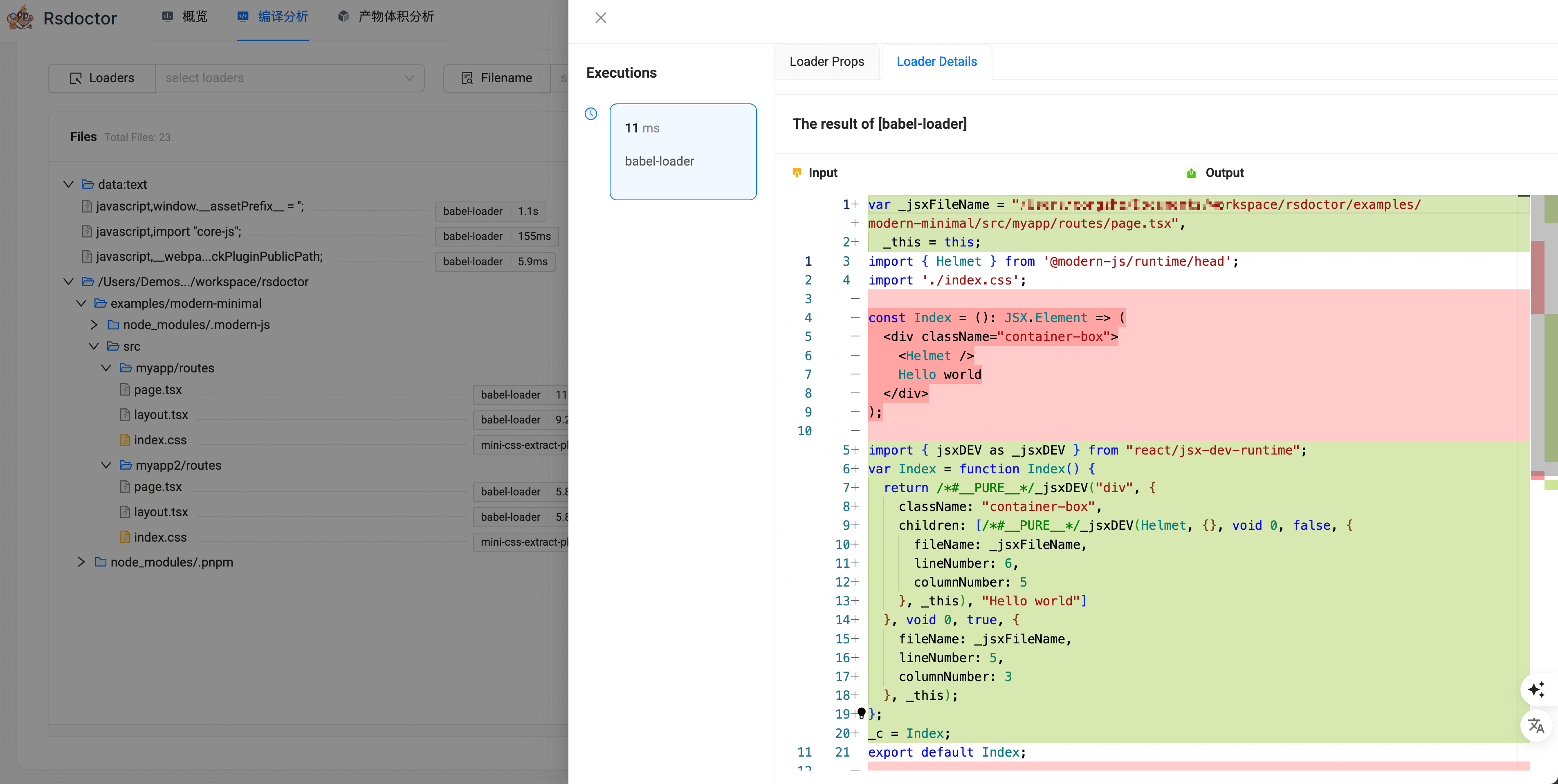
通过 点击文件 则会弹出一个遮罩层,其中是 当前点击的文件 所有执行过的 Loader 列表,通过点击选中对应的 Loader 可以看到目标 Loader 调用时的输入输出和参数数据信息。

- 参数数据信息:点击「show more」或者左上角展开按钮,可查看对应参数信息。
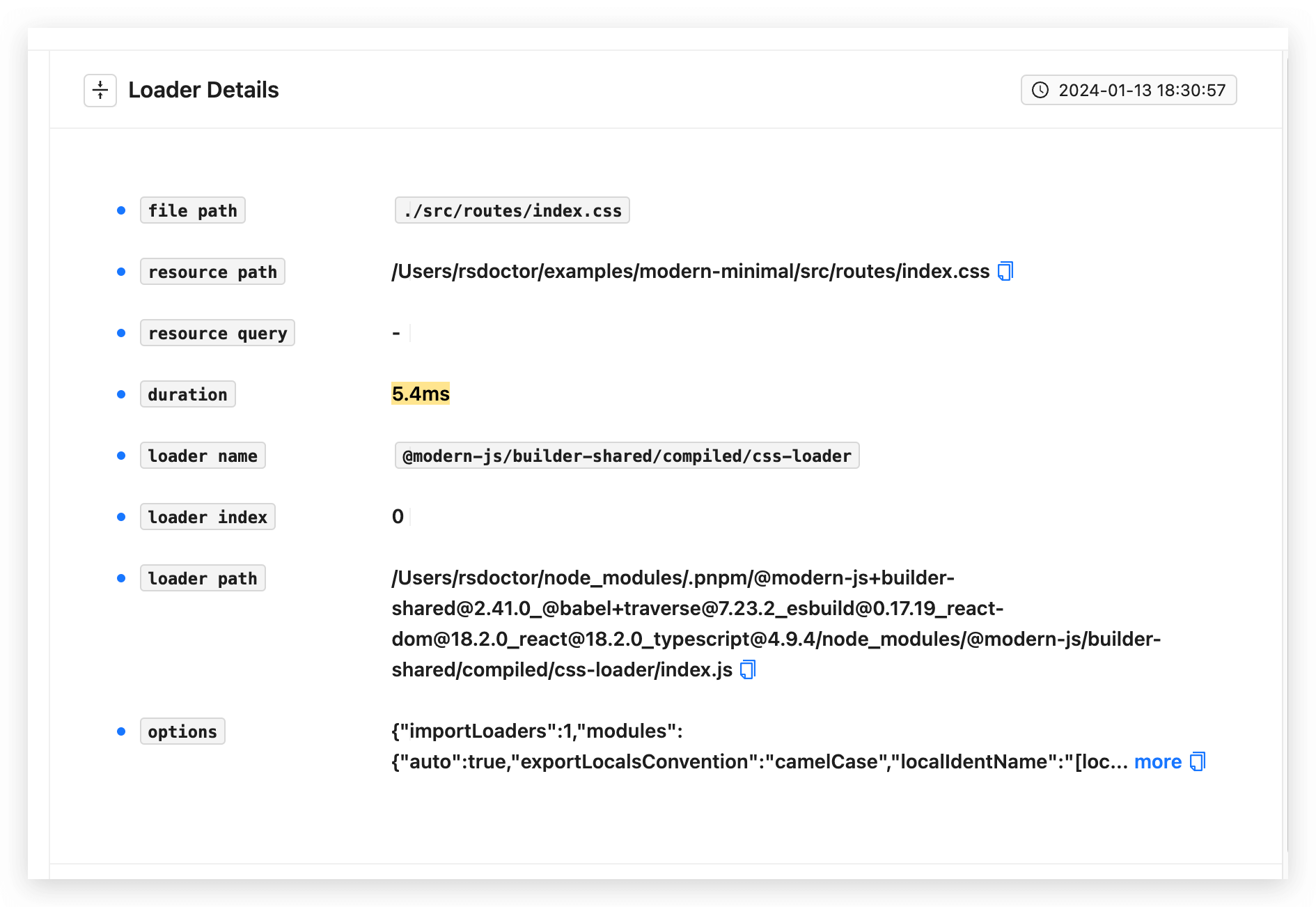
我们可以通过此处单个文件的 Loader 信息来排查问题,以及决策是不是该被添加到 module.rule.exclude 中。
通常来说,在 项目外(即 cwd 之外,通常为 workspace) 内的一些内部包,我们可以跟据目录的 Loader 耗时信息 以及 单个文件的输入输入信息(因为这些内部包有可能已经是兼容性比较好的 ES 语法),来判断我们是不是有必要要给这个目录设置 module.rule.exclude。
了解更多
你可能想要了解更多关于 Loader 分析模块的使用介绍: